Performance issues in a map reduce jobs is a common problem faced by hadoop developers and there are a few hadoop specific usual suspects that are worth checking to see whether they are responsible for a performance problem. Below is the list
Number of mappers – First thing to check is how long are your mappers running for and if they are only running for a few seconds on average, you should see whether there’s a way to have fewer mappers and make them all run longer than a minute or so, as a rule of thumb. The extent to which this is possible depends on the input format you are using.
Hadoop works better with a small number of large files than a large number of small files. One reason for this is that FileInputFormat generates splits in such a way that each split is all or part of a single file. If the file is very small compared to an HDFS block and there are a lot of them, each map task will process very little input, and there will be a lot of them (one per file), each of which imposes extra bookkeeping overhead. Compare a 1 GB file broken into eight 128 MB blocks with 10,000 or so 100 KB files. The 10,000 files use one map each, and the job time can be tens or hundreds of times slower than the equivalent one with a single input file and eight map tasks.
The situation is alleviated somewhat by CombineFileInputFormat, which was designed to work well with small files. Where FileInputFormat creates a split per file, CombineFileInputFormat packs many files into each split so that each mapper has more to process. Crucially, CombineFileInputFormat takes node and rack locality into account when deciding which blocks to place in the same split, so it does not compromise the speed at which it can process the input in a typical MapReduce job.
Of course, if possible, it is still a good idea to avoid the many small files case, because MapReduce works best when it can operate at the transfer rate of the disks in the cluster, and processing many small files increases the number of seeks that are needed to run a job. Also, storing large numbers of small files in HDFS is wasteful of the namenode’s memory. One technique for avoiding the many small files case is to merge small files into larger files by using a sequence file with this approach, the keys can act as filenames (or a constant such as NullWritable, if not needed) and the values as file contents. But if you already have a large number of small files in HDFS, then
CombineFileInputFormat is worth trying.
Note : CombineFileInputFormat isn’t just good for small files. It can bring benefits when processing large files, too, since it will generate one split per node, which may be made up of multiple blocks. Essentially, CombineFileInputFormat decouples the amount of data that a mapper consumes from the block size of the files in HDFS.
Number of reducers – Check that you are using more than a single reducer. Choosing the number of reducers for a job is more of an art than a science. Increasing the number of reducers makes the reduce phase shorter, since you get more parallelism. However, if you take this too far, if you can have lots of small files, which is suboptimal.One rule of thumb is to aim for reducers that each run for five minutes or so, and which produce at least one HDFS block’s worth of output.
Combiners – Check whether your job can take advantage of a combiner to reduce the amount of data passing through the shuffle.
Intermediate compression – Job execution time can almost always benefit from enabling map output compression.The configuration properties to set compression for MapReduce job outputs are mapreduce.output.fileoutputformat.compress which needs to be set to true, mapreduce.output.fileoutputformat.compress.codec is the compression codec to use for outputs, mapreduce.output.fileoutputformat.compress.type .The type of compression to use for sequence file outputs allowed values are NONE,RECORD, or BLOCK
Custom serialization – If you are using your own custom Writable objects or custom comparators, make sure you have implemented RawComparator.
WritableComparable and comparators used as a key in MapReduce have to be deserialized into an object for the compareTo() method to be invoked. But we should consider if possible to compare two objects just by looking at their serialized representations.
WritableComparator has a compare method which will take the byte representation
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2)
Tuning shuffle phase to improve mapreduce performance – The MapReduce shuffle exposes around a dozen tuning parameters for memory management, which may help you wring out the last bit of performance.
The general principle is to give the shuffle as much memory as possible. However, there is a trade-off, in that you need to make sure that your map and reduce functions get enough memory to operate. This is why it is best to write your map and reduce functions to use as little memory as possible—certainly they should not use an unbounded amount of memory like avoid accumulating values in a map.
The amount of memory given to the JVMs in which the map and reduce tasks run is set by the mapred.child.java.opts property. You should try to make this as large as possible for the amount of memory on your task nodes.
On the map side, the best performance can be obtained by avoiding multiple spills to disk and one is optimal. If you can estimate the size of your map outputs, you can set the mapreduce.task.io.sort.* properties appropriately to minimize the number of spills. In particular, you should increase mapreduce.task.io.sort.mb if you can. There is a MapReduce counter SPILLED_RECORDS that counts the total number of records that were spilled to disk over the course of a job, which can be useful for tuning. Note that the counter includes both map- and reduce-side spill.
On the reduce side, the best performance is obtained when the intermediate data can reside entirely in memory. This does not happen by default, since for the general case all the memory is reserved for the reduce function. But if your reduce function has light memory requirements, setting mapreduce.reduce.merge.inmem.threshold to 0 and mapreduce.reduce.input.buffer.percent to 1.0 or a lower value may bring a performance boost. One of the optimizations that can be used is to keep the intermediate data in memory on the reduce side.
More generally, Hadoop uses a buffer size of 4 KB by default, which is low, so you should increase this across the cluster by setting io.file.buffer.size.
Map-side tuning properties
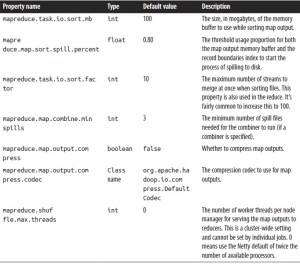
Reduce-side tuning properties


Profiling Tasks
Hadoop allows you to profile a fraction of the tasks in a job and, as each task completes, pulls down the profile information to your machine for later analysis with standard profiling tools.Of course, it’s possible, and somewhat easier, to profile a job running in the local job runner. And provided you can run with enough input data to exercise the map and reduce tasks, this can be a valuable way of improving the performance of your mappers and reducers.
There are a couple of caveats, however. The local job runner is a very different environment from a cluster, and the data flow patterns are very different. Optimizing the CPU performance of your code may be pointless if your MapReduce job is I/O-bound (as many jobs are). To be sure that any tuning is effective, you should compare the new execution time with the old one running on a real cluster. Even this is easier said than done, since job execution times can vary due to resource contention with other jobs and the decisions the scheduler makes regarding task placement. To get a good idea of job execution time under these circumstances, perform a series of runs with and without the change and check whether any improvement is statistically significant. It’s unfortunately true that some problems such as excessive memory use can be reproduced only on the cluster.
The HPROF profiler
There are a number of configuration properties to control profiling, which are also exposed via convenience methods on JobConf. Enabling profiling is as simple as setting the property mapreduce.task.profile to true.
hadoop jar hadoop-usecase.jar driverClass -D mapreduce.task.profile=true
This runs the job as normal, but adds an -agentlib parameter to the Java command used to launch the task containers on the node managers. You can control the precise parameter that is added by setting the mapreduce.task.profile.params property. The default uses HPROF, a profiling tool that comes with the JDK that, although basic, can give valuable information about a program’s CPU and heap usage.
It doesn’t usually make sense to profile all tasks in the job, so by default only those with IDs 0, 1, and 2 are profiled (for both maps and reduces). You can change this by setting mapreduce.task.profile.maps and mapreduce.task.profile.reduces to specify the
range of task IDs to profile.
The profile output for each task is saved with the task logs in the user logs subdirectory of the node manager’s local log directory.
Memory settings in YARN and MapReduce
YARN treats memory in a more fine-grained manner than the slot-based model used in MapReduce 1. Rather than specifying a fixed maximum number of map and reduce slots that may run on a node at once, YARN allows applications to request an arbitrary amount of memory (within limits) for a task. In the YARN model, node managers allocate memory from a pool, so the number of tasks that are running on a particular node depends on the sum of their memory requirements, and not simply on a fixed number of slots.
The calculation for how much memory to dedicate to a node manager for running containers depends on the amount of physical memory on the machine. Each Hadoop daemon uses 1,000 MB, so for a datanode and a node manager, the total is 2,000 MB. Set aside enough for other processes that are running on the machine, and the remainder can be dedicated to the node manager’s containers by setting the configuration property yarn.nodemanager.resource.memory-mb to the total allocation in MB. The default is 8,192 MB, which is normally too low for most setups.
The next step is to determine how to set memory options for individual jobs. There are two main controls: one for the size of the container allocated by YARN, and another for the heap size of the Java process run in the container. The memory controls for MapReduce are all set by the client in the job configuration. The YARN settings are cluster settings and cannot be modified by the client.
Container sizes are determined by mapreduce.map.memory.mb and mapreduce.reduce.memory.mb both default to 1,024 MB. These settings are used by the application master when negotiating for resources in the cluster, and also by the node manager, which runs and monitors the task containers. The heap size of the Java process is set by mapred.child.java.opts, and defaults to 200 MB. You can also set the Java options separately for map and reduce tasks.

Lets say mapred.child.java.opts is set to -Xmx800m and mapreduce.map.memory.mb is left at its default value of 1,024 MB. When a map task is run, the node manager will allocate a 1,024 MB container (decreasing the size of its pool by that amount for the duration of the task) and will launch the task JVM configured with an 800 MB maximum heap size. Note that the JVM process will have a larger memory footprint than the heap size, and the overhead will depend on such things as the native libraries that are in use, the size of the permanent generation space, and so on. The important thing is that the physical memory used by the JVM process, including any processes that it spawns, such as Streaming processes, does not exceed its allocation (1,024 MB). If a container uses more memory than it has been allocated, then it may be terminated by the node manager and marked as failed.
YARN schedulers impose a minimum or maximum on memory allocations. The default minimum is 1,024 MB set by yarn.scheduler.minimum-allocation-mb , and the default maximum is 8,192 MB set by yarn.scheduler.maximum-allocation-mb.
There are also virtual memory constraints that a container must meet. If a container’s virtual memory usage exceeds a given multiple of the allocated physical memory, the node manager may terminate the process. The multiple is expressed by the yarn.nodemanager.vmem-pmem-ratio property, which defaults to 2.1. In the example used earlier, the virtual memory threshold above which the task may be terminated is 2,150 MB, which is 2.1 × 1,024 MB.
When configuring memory parameters it’s very useful to be able to monitor a task’s actual memory usage during a job run, and this is possible via MapReduce task counters. The counters PHYSICAL_MEMORY_BYTES, VIRTUAL_MEMORY_BYTES, and COMMITTED_HEAP_BYTES provide snapshot values of memory usage and are therefore suitable for observation during the course of a task attempt.
CPU settings in YARN and MapReduce
In addition to memory, YARN treats CPU usage as a managed resource, and applications can request the number of cores they need. The number of cores that a node manager can allocate to containers is controlled by the yarn.nodemanager.resource.cpuvcores property. It should be set to the total number of cores on the machine, minus a core for each daemon process running on the machine like datanode, node manager, and any other long-running processes. MapReduce jobs can control the number of cores allocated to map and reduce containers by setting mapreduce.map.cpu.vcores and mapreduce.reduce.cpu.vcores. Both default to 1, an appropriate setting for normal single-threaded MapReduce tasks, which can only saturate a single core.
While the number of cores is tracked during scheduling so a container won’t be allocated on a machine where there are no spare cores available, the node manager will not, by default, limit actual CPU usage of running containers. This means that a container can abuse its allocation by using more CPU than it was given, possibly starving other containers running on the same host. YARN has support for enforcing CPU limits using Linux cgroups. The node manager’s container executor class yarn.nodemanager.containerexecutor.class must be set to use the LinuxContainerExecutor class, which in turn must be configured to use cgroups.